5 栅格化参数优化
为什么要将数据聚合到栅格中?
为什么我们要将数据聚合到栅格中?
离散化
在连续空间中难以分析数据,但易于使用离散区域进行分析。定义空间分析单位可以使区域离散化。
比较
所有栅格的大小相同,其属性在相同标准下具有可比性。
可控
在栅格框架下,聚合精度可控。定义较小的栅格将提高准确性,但会增加计算负担。
高效
使用TransBigData,GPS数据可以与计算复杂度较小的栅格相匹配。栅格与GPS数据匹配的计算速度快。
在TransBigData中,栅格化框架由栅格化参数确定。每个格网参数都可以定义一个格网坐标系。参数如下:
params=(lonStart,latStart,deltaLon,deltaLat,theta)
然而,在我们的研究中如何选择合适的栅格参数是最基本的事情,这可能对最终的分析结果产生很大的影响。
栅格的选择取决于数据和分析的目的。
假设我们想使用栅格系统来分析车辆行驶轨迹。如果格网边界与道路中心线重合,则穿过路段的车辆将沿格网边界生成 GPS 点。即使车辆通过同一路段,将GPS与栅格匹配后生成的栅格序列也会有很大差异。换句话说,更好的格网坐标系应该是通过同一路径的轨迹应该具有相似的格网序列。
一个好主意是输入城市路网数据并从路网优化栅格参数。但是,对于像TransBigData这样的栅格框架,这不是最好的解决方案。我们要分析的GPS数据不仅是车辆轨迹数据,它们也不必遵循给定的道路网络。此外,道路网络的空间特征已经包含在车辆轨迹中。因此,格网参数的选择应取决于GPS数据的原始空间属性。
在分析个人移动数据时,最佳栅格选择标准也不同。由于个人通常会停留更多时间并在其活动点中生成更多数据,因此更好的栅格化应将这些数据匹配到同一栅格中。结果应该是很少有栅格占用更多数据。
在这里,我们提供了三种方法来优化栅格参数:centerdist,gini和gridscount
[1]:
import pandas as pd
import geopandas as gpd
import transbigdata as tbd
#Read taxi gps data
tripdata = pd.read_csv(r'data/TaxiData-Sample.csv')
tripdata.columns = ['track_id','time','lon','lat','OpenStatus','Speed']
#Retain the data in given area
area = gpd.read_file(r'data/gis/szarea1.json')
tripdata = tbd.clean_outofshape(tripdata,area,col=['lon','lat'])
#Generate initial griding params
bounds = [113.6,22.4,114.8,22.9]
initialparams = tbd.area_to_params(bounds,accuracy = 500)
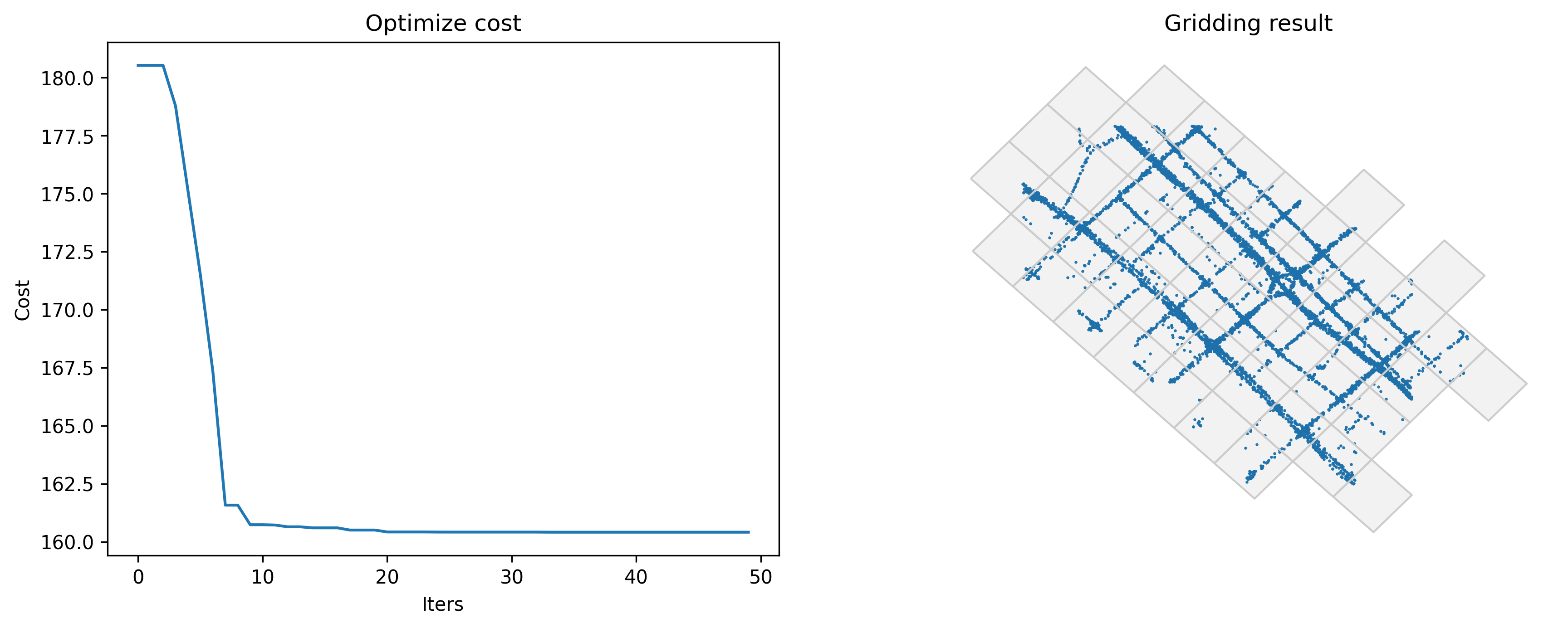
centerdist: 最小化栅格中心与GPS数据的距离
当一批距离很近的数据分布在栅格边缘时,GPS数据的偏差会导致这些数据被匹配到不同的栅格中。因此,解决方案之一是最小化栅格中心和GPS数据之间的距离。
[2]:
#Optimize gridding params
params_optimized = tbd.grid_params_optimize(tripdata,
initialparams,
col=['track_id','lon','lat'],
optmethod='centerdist',
sample=0, #not sampling
printlog=True)
Optimized index centerdist: 160.41280636449184
Optimized gridding params: {'slon': 113.60144616975187, 'slat': 22.401543058590295, 'deltalon': 0.004872390756896538, 'deltalat': 0.004496605206422906, 'theta': 43.585298279322615, 'method': 'rect'}
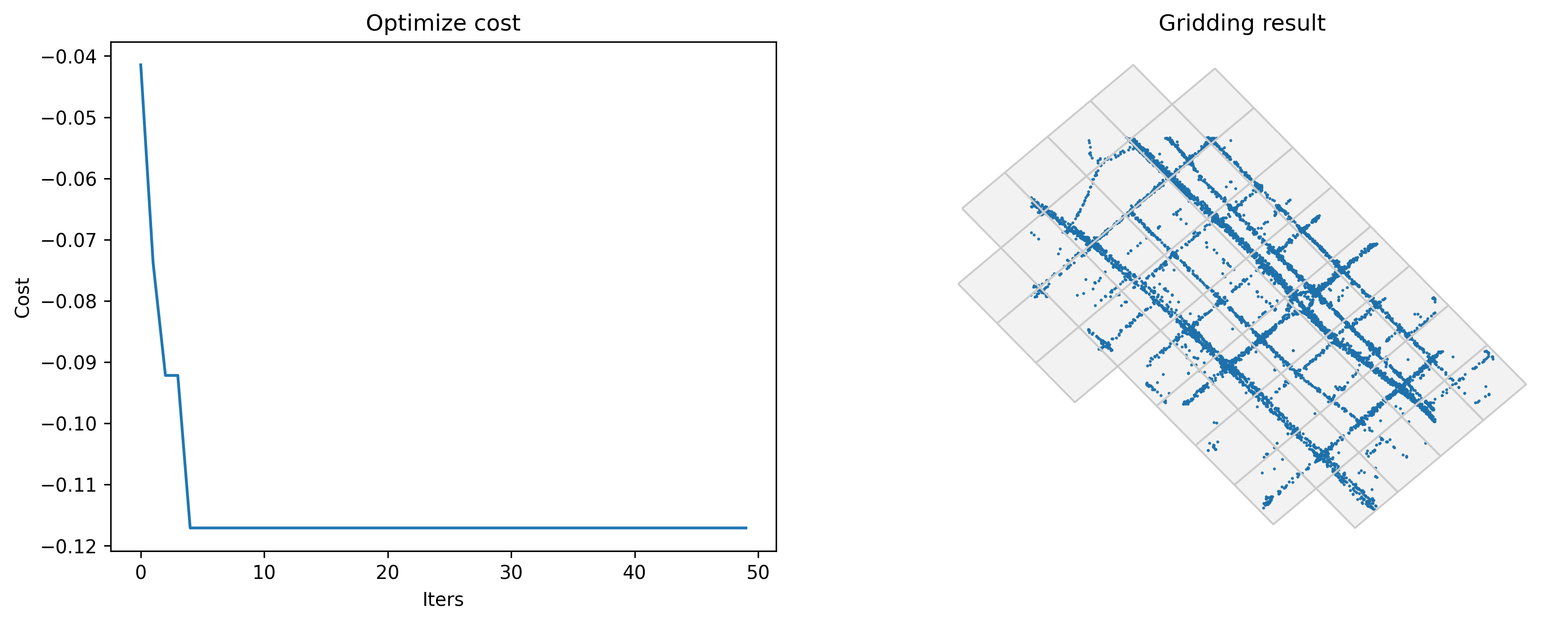
gini:最大化基尼指数
在经济学中,基尼指数是统计离散的衡量标准,旨在代表一个国家或社会群体内的收入不平等或财富不平等。在这里,我们可以借用基尼指数的概念来表示GPS数据在栅格中的分布。基尼指数的较高值表示数据在给定栅格中的分布更集中。
基尼指数对分析人员流动数据更有帮助。
[3]:
#Optimize griding params
params_optimized = tbd.grid_params_optimize(tripdata,
initialparams,
col=['track_id','lon','lat'],
optmethod='gini',
sample=0, #not sampling
printlog=True)
Optimized index gini: -0.11709661279249717
Optimized gridding params: {'slon': 113.60363252207824, 'slat': 22.40161914185426, 'deltalon': 0.004872390756896538, 'deltalat': 0.004496605206422906, 'theta': 47.730990684694575, 'method': 'rect'}
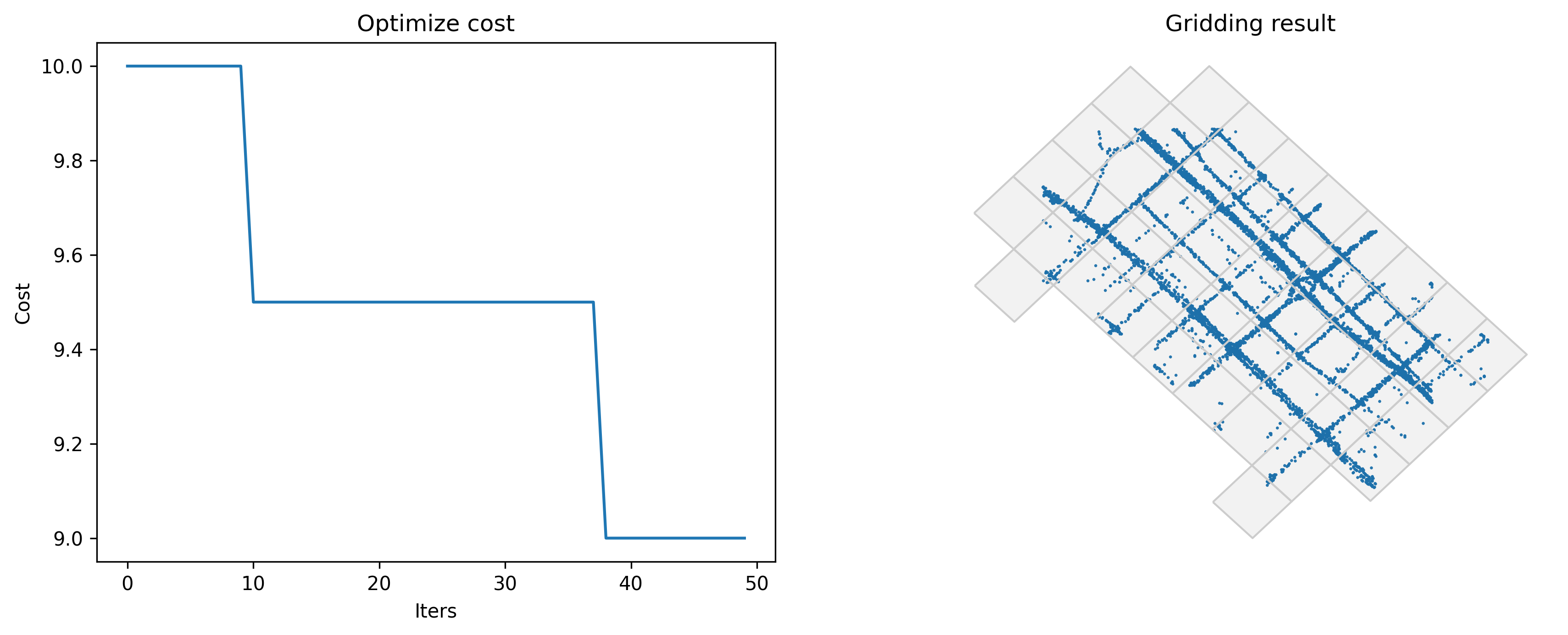
gridscount: 最小化个体的栅格平均数
在此标准下,每个人都应出现在尽可能少的栅格中。
[4]:
#Optimize griding params
params_optimized = tbd.grid_params_optimize(tripdata,
initialparams,
col=['track_id','lon','lat'],
optmethod='gridscount',
sample=0, #not sampling
printlog=True)
Optimized index gridscount: 9.0
Optimized gridding params: {'slon': 113.60372085909265, 'slat': 22.403002740815666, 'deltalon': 0.004872390756896538, 'deltalat': 0.004496605206422906, 'theta': 44.56000665402531, 'method': 'rect'}
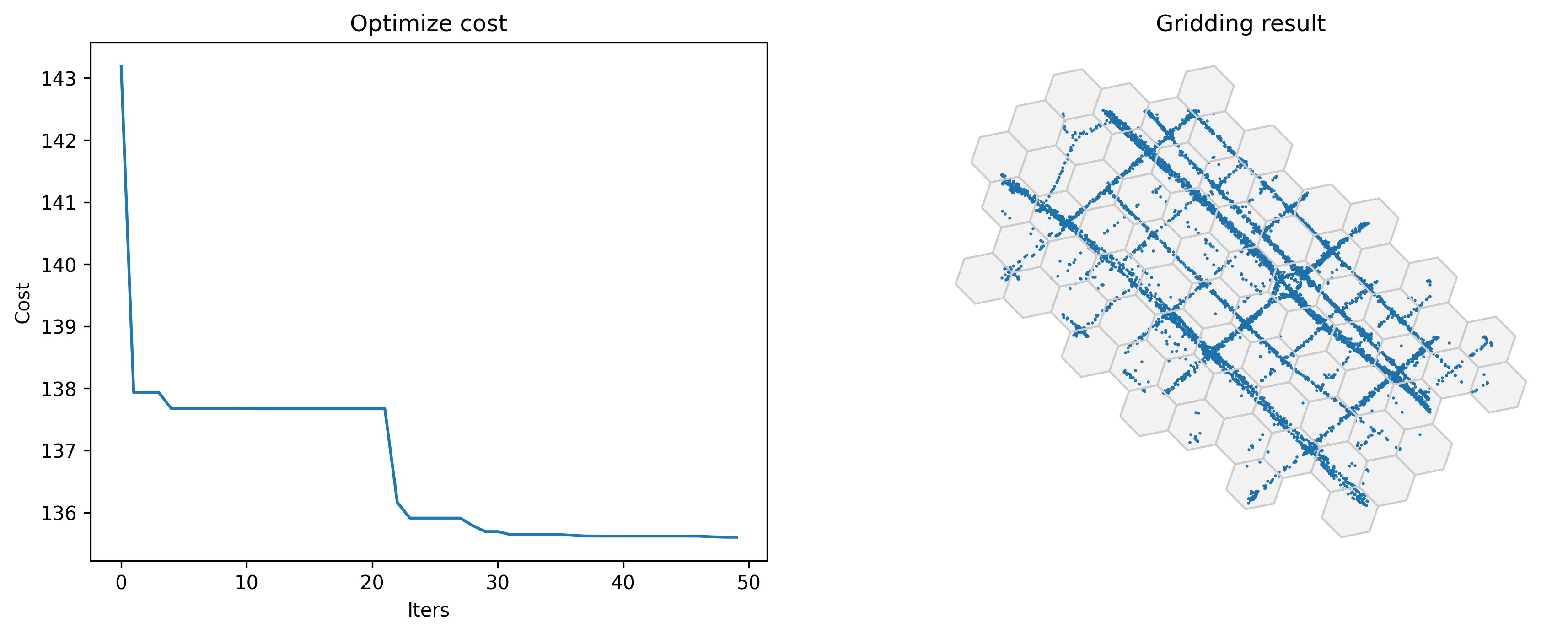
还支持优化三角形和六边形栅格化参数
[5]:
initialparams['method'] = 'tri'
[6]:
#Optimize gridding params
params_optimized = tbd.grid_params_optimize(tripdata,
initialparams,
col=['track_id','lon','lat'],
optmethod='centerdist',
sample=0, #not sampling
printlog=True)
Optimized index centerdist: 136.87564489047065
Optimized gridding params: {'slon': 113.60421146982776, 'slat': 22.402738210124514, 'deltalon': 0.004872390756896538, 'deltalat': 0.004496605206422906, 'theta': 31.61303640854649, 'method': 'tri'}

[7]:
initialparams = tbd.area_to_params(bounds,accuracy = 500/(6**0.5))
initialparams['method'] = 'hexa'
[8]:
#Optimize gridding params
params_optimized = tbd.grid_params_optimize(tripdata,
initialparams,
col=['track_id','lon','lat'],
optmethod='centerdist',
sample=0, #not sampling
printlog=True)
Optimized index centerdist: 135.60103782128888
Optimized gridding params: {'slon': 113.60043088516572, 'slat': 22.400303375881162, 'deltalon': 0.0019891451969749397, 'deltalat': 0.0018357313884130575, 'theta': 17.62535531106509, 'method': 'hexa'}