3 车辆轨迹数据处理
对于车辆轨迹数据,TransBigData 库 0.5.0 及以上版本提供了一套轨迹数据处理方法。这些方法包括轨迹数据的预处理和漂移校正、停靠点和行程的分割、基于格网的表示、可视化等。本文将介绍如何使用TransBigData库来处理轨迹数据。
[1]:
import pandas as pd
import geopandas as gpd
import transbigdata as tbd
# ensure tbd version is above 0.5.0
tbd.__version__
[1]:
'0.5.0'
轨迹数据质量
首先,我们读取数据并观察基本信息以检查是否有任何缺失值。使用DataFrame的内置方法,我们可以轻松查看数据的基本信息,包括数据类型,字段数,行数以及是否存在缺失值。代码如下:
[2]:
# Read the data
data = pd.read_csv('data/TaxiData-Sample.csv', header=None)
data.columns = ['id', 'time', 'lon', 'lat', 'OpenStatus', 'speed']
# Convert the time format
data['time'] = pd.to_datetime(data['time'])
data
[2]:
| id | time | lon | lat | OpenStatus | speed | |
|---|---|---|---|---|---|---|
| 0 | 34745 | 2023-05-29 20:27:43 | 113.806847 | 22.623249 | 1 | 27 |
| 1 | 34745 | 2023-05-29 20:24:07 | 113.809898 | 22.627399 | 0 | 0 |
| 2 | 34745 | 2023-05-29 20:24:27 | 113.809898 | 22.627399 | 0 | 0 |
| 3 | 34745 | 2023-05-29 20:22:07 | 113.811348 | 22.628067 | 0 | 0 |
| 4 | 34745 | 2023-05-29 20:10:06 | 113.819885 | 22.647800 | 0 | 54 |
| ... | ... | ... | ... | ... | ... | ... |
| 544994 | 28265 | 2023-05-29 21:35:13 | 114.321503 | 22.709499 | 0 | 18 |
| 544995 | 28265 | 2023-05-29 09:08:02 | 114.322701 | 22.681700 | 0 | 0 |
| 544996 | 28265 | 2023-05-29 09:14:31 | 114.336700 | 22.690100 | 0 | 0 |
| 544997 | 28265 | 2023-05-29 21:19:12 | 114.352600 | 22.728399 | 0 | 0 |
| 544998 | 28265 | 2023-05-29 19:08:06 | 114.137703 | 22.621700 | 0 | 0 |
544999 rows × 6 columns
[3]:
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 544999 entries, 0 to 544998
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 544999 non-null int64
1 time 544999 non-null datetime64[ns]
2 lon 544999 non-null float64
3 lat 544999 non-null float64
4 OpenStatus 544999 non-null int64
5 speed 544999 non-null int64
dtypes: datetime64[ns](1), float64(2), int64(3)
memory usage: 24.9 MB
其中列出了数据字段的数据类型、非空值的数量和内存使用情况。在“非空”列中,列出了每个字段的非空值的数量。如果字段的非空值数小于总行数,则表示该字段中存在缺失值。
接下来,我们将使用 TransBigData 生成数据质量报告,并观察数据中的车辆数量、观察时间段和采样间隔:
[4]:
# Generate data quality report
tbd.data_summary(data,col=['id', 'time'],show_sample_duration=True)
Amount of data
-----------------
Total number of data items: 544999
Total number of individuals: 180
Data volume of individuals(Mean): 3027.7722
Data volume of individuals(Upper quartile): 4056.25
Data volume of individuals(Median): 2600.5
Data volume of individuals(Lower quartile): 1595.75
Data time period
-----------------
Start time: 2023-05-29 00:00:00
End time: 2023-05-29 23:59:59
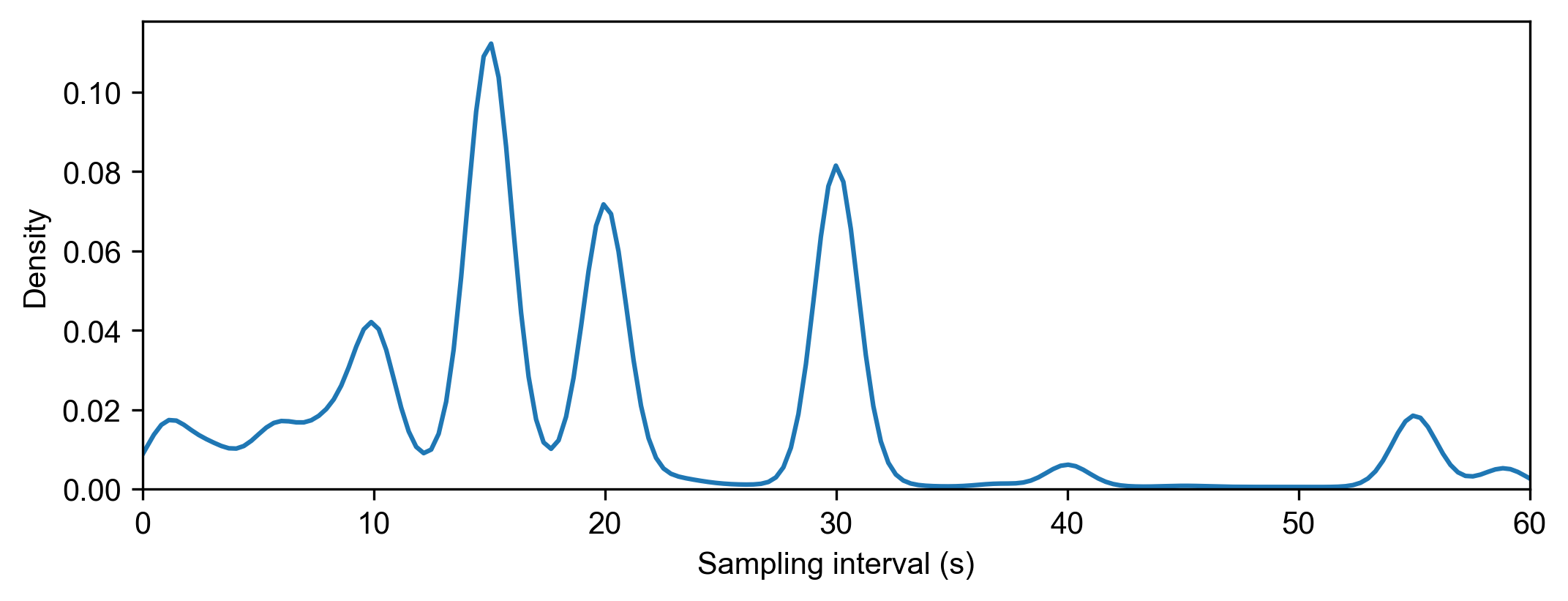
Sampling interval
-----------------
Mean: 27.995 s
Upper quartile: 30.0 s
Median: 20.0 s
Lower quartile: 15.0 s
冗余消除
消除冗余是清理轨迹数据的重要步骤。它减少了数据量,提高了数据处理效率,而不会影响数据中包含的信息。在实际的轨迹数据处理中,您可能会遇到以下两种类型的冗余:
同一时刻重复数据的冗余:
在轨迹数据集中,同一车辆在同一时刻可能有多个轨迹数据条目。当采样间隔与数据集中时间字段的精度相比太短时,可能会发生这种情况。例如,如果采样间隔为 1 秒,但数据集中的时间字段的精度为 1 分钟,则可能导致同一车辆在同一分钟内出现多个轨迹数据条目。不删除这些冗余数据可能会导致后续处理困难。消除这种冗余的方法很简单:在同一时刻只保留同一车辆的一个轨迹数据条目。
车辆停止的冗余:
在车辆轨迹数据中,采样间隔通常很短,例如每隔几秒钟收集一次数据。这意味着无论车辆是移动还是静止,都会持续生成数据。在实际应用中,重点通常是车辆在行驶期间的轨迹,而不是在停车期间。对于车辆停止的每个实例,我们只需要知道停止的开始和结束时间。在停靠点中间部分(位于同一位置)生成的数据是冗余的,可以将其删除以减小整体数据大小。对于具有相同位置的连续 n 个数据条目序列 (n>=3),我们只需要保留第一个和最后一个条目,因为中间数据是多余的。在代码中,将每个数据条目的车辆 ID 和经纬度与上一个和下一个轨迹条目进行比较就足够了。如果它们相同,则可以删除数据。
但是,上述车辆停靠点的冗余消除方法不考虑车辆ID,时间和经纬度以外的字段所携带的信息。例如,对于出租车车辆,乘客可以在停车期间登上出租车,将状态从“空置”更改为“占用”。在这种情况下,需要保留此信息。
TransBigData提供了一个功能“tbd.traj_clean_redundant()”,用于轨迹数据冗余消除。它可以处理上述冗余情况,还可以检测车辆ID和经纬度以外的字段中的冗余。代码如下:
[5]:
# data volume before Redundancy Elimination
len(data)
[5]:
544999
[6]:
# Data redundancy removal to reduce data size and improve computational efficiency in subsequent steps
#
data = tbd.traj_clean_redundant(
data,
col=['id', 'time', 'lon', 'lat', 'speed'] # Apart from vehicle ID, time, longitude, and latitude, consider whether the speed field has redundancy
)
len(data)
[6]:
421099
代码片段执行数据冗余删除,以减小数据大小并提高计算效率。“tbd”模块中的“traj_clean_redundant”函数用于此目的。该函数将“data”变量作为输入,并指定要考虑删除冗余的列(“col”),包括车辆ID,时间,经度,纬度和可选的速度字段。结果被存储回“data”变量中,并输出更新数据的长度。
漂移清理
在车辆轨迹数据中,由于数据采集设备错误、环境干扰、设备故障、GPS信号不稳定、卫星覆盖不足、信号障碍等因素,采集的车辆轨迹数据与实际情况之间可能会出现偏差和误差。这会导致轨迹数据的实际位置与收集的位置之间存在差异,这在车辆轨迹数据中称为数据漂移。在数据中,数据漂移表现为轨迹数据点与实际位置之间的距离很大,通常伴随着突然的跳跃。这种漂移会影响后续的空间分析和空间统计,需要清理车辆轨迹数据以确保数据的准确性和可用性。
要清除车辆轨迹数据以查找漂移,一种方法是移除定义研究区域之外的轨迹数据点。可以通过两种方式定义研究区域:通过指定左下角和右上角坐标来确定边界范围(边界),或者使用表示研究区域的地理信息文件(geojson 或 shapefile)。
要使用 geojson 或 shapefile 删除漂移数据,首先需要在 GeoPandas 中将 geojson 或 shapefile 读取为“GeoDataFrame”类型。然后,您可以使用 GeoPandas 提供的“intersects()”方法来确定轨迹数据是否在研究区域内。但是,此方法需要对每个轨迹数据点执行空间几何匹配,这对于大型数据集可能非常耗时。TransBigData 包中提供的“tbd.clean_outofshape()”方法提供了一种更有效的方法。它首先使用内置的栅格分区方法将轨迹数据映射到相应的栅格,然后基于栅格进行空间匹配,显着提高清理效率。
下面是一个使用TransBigData的“clean_outofshape()”方法进行数据偏移清理的示例代码片段:
[7]:
# Read the research area range
sz = gpd.read_file('Data/sz.json')
sz.plot()
[7]:
<AxesSubplot:>
[8]:
# Data drift removal
# Removing data outside the study area
data = tbd.clean_outofshape(data, sz, col=['lon', 'lat'], accuracy=500)
len(data)
[8]:
419448
要清理研究区域内的轨迹漂移,需要根据轨迹的连续变化进行评估和清理。有三种常见的清洁方法:
速度阈值法:如果当前轨迹数据与之前和后续轨迹之间的速度超过阈值,则视为漂移。
距离阈值法:如果当前轨迹数据与上一个和后续轨迹之间的距离超过阈值,则视为漂移。
角度阈值法:如果前一个、当前和后续轨迹形成的角度小于阈值,则视为漂移。
在TransBigData中,提供了“tbd.traj_clean_drift()”方法来清理多个车辆的轨迹数据。此方法将距离、速度和角度阈值集成到单个函数中。
下面是使用TransBigData的“traj_clean_drift()”方法的示例代码片段:
[9]:
# Drift cleaning within the study area using speed, distance, and angle as criteria
data = tbd.traj_clean_drift(
data, # Trajectory data, can include data for multiple vehicles, distinguished by ID
col=['id', 'time', 'lon', 'lat'], # Column names of the trajectory data
speedlimit=80, # Speed threshold in km/h, set to None to skip speed-based filtering
dislimit=4000, # Distance threshold in meters, set to None to skip distance-based filtering
anglelimit=30) # Angle threshold in degrees, set to None to skip angle-based filtering
len(data)
[9]:
405286
停止和行程提取
在车辆轨迹数据的长期连续观测中,常见的要求是从轨迹数据中提取停靠点和行程。可以分析停靠点以确定车辆停车的持续时间和位置,同时可以进一步分析行程以提取信息,例如每次行程的起点和目的地、行驶路径、行驶持续时间、行驶距离和行驶速度。在本节中,我们将解释如何从车辆轨迹中识别停靠点和行程,提取每个行程的轨迹信息,并生成轨迹线。
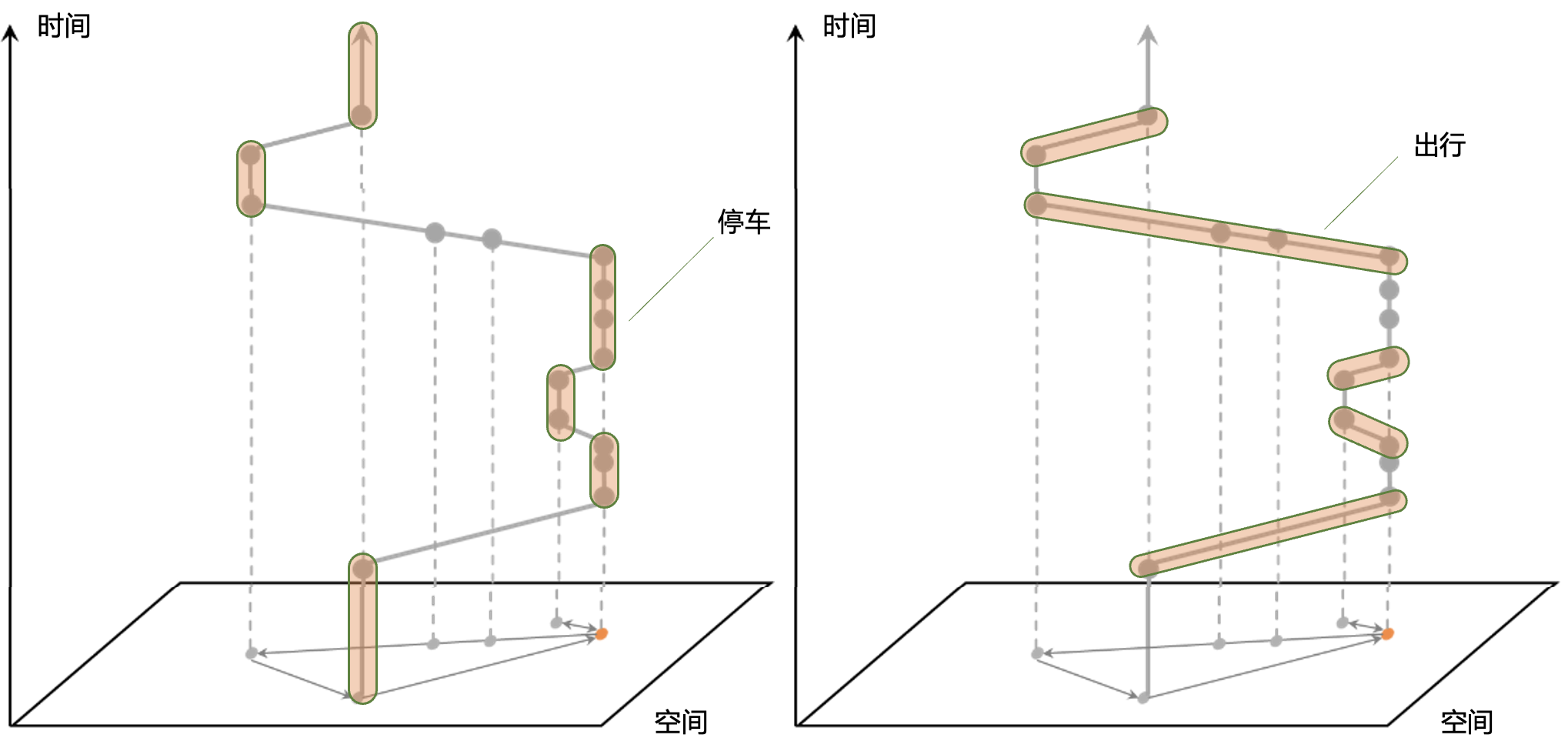
在车辆轨迹数据中,通常使用时间阈值方法标识停靠点和行程。方法如下:为了避免轨迹数据的波动,我们需要在地理空间中预定义一个栅格。如果两个连续数据点之间的持续时间超过我们设定的阈值(通常为 30 分钟),我们将其视为止损。两个停靠点之间的时间段被视为一个行程,如下图所示。
清理轨迹数据后,我们需要定义一个格网坐标系,并将轨迹数据转换为基于格网的表示,以识别停靠点和行程。
[11]:
# Define the grid parameters
bounds = [113.75, 22.4, 114.62, 22.86]
params = tbd.area_to_params(bounds,accuracy = 100)
params
[11]:
{'slon': 113.75,
'slat': 22.4,
'deltalon': 0.0009743362892898221,
'deltalat': 0.0008993210412845813,
'theta': 0,
'method': 'rect',
'gridsize': 100}
TransBigData包中通过“tbd.traj_stay_move()”功能提供了停靠点和行程的标识。这是代码:
[12]:
# Identify stay and move
stay, move = tbd.traj_stay_move(data, params, col=['id', 'time', 'lon', 'lat'], activitytime=1800)
len(stay), len(move)
[12]:
(545, 725)
在代码中,“data”表示清理后的轨迹数据。“traj_stay_move()”函数用于根据指定的停靠点阈值识别停靠点和行程。它返回两个输出:“停止”和“行程”,分别包含标识的停靠点和行程。您可以利用这些数据进行进一步分析。
注意:“tbd.traj_stay_move()”函数不会删除持续时间为 0 的行程。这是因为某些轨迹数据可能具有较长的采样间隔,可能无法捕获两个停靠点之间的行驶过程。因此,这些行程的计算持续时间将为 0。
[13]:
stay
[13]:
| id | stime | LONCOL | LATCOL | etime | lon | lat | duration | stayid | |
|---|---|---|---|---|---|---|---|---|---|
| 23320 | 22396 | 2023-05-29 06:10:09 | 262 | 284 | 2023-05-29 07:56:32 | 114.005547 | 22.655800 | 6383.0 | 0 |
| 51327 | 22396 | 2023-05-29 12:51:23 | 50 | 429 | 2023-05-29 16:44:57 | 113.798630 | 22.786167 | 14014.0 | 1 |
| 54670 | 22413 | 2023-05-29 00:00:09 | 145 | 431 | 2023-05-29 01:22:41 | 113.891403 | 22.787300 | 4952.0 | 2 |
| 54722 | 22413 | 2023-05-29 01:25:13 | 145 | 431 | 2023-05-29 02:01:44 | 113.891701 | 22.787399 | 2191.0 | 3 |
| 54741 | 22413 | 2023-05-29 02:18:13 | 145 | 431 | 2023-05-29 02:48:46 | 113.891502 | 22.787300 | 1833.0 | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 151140 | 36686 | 2023-05-29 01:04:37 | 323 | 172 | 2023-05-29 02:33:37 | 114.065193 | 22.554672 | 5340.0 | 540 |
| 154762 | 36686 | 2023-05-29 03:03:07 | 307 | 185 | 2023-05-29 03:51:07 | 114.048721 | 22.566692 | 2880.0 | 541 |
| 154924 | 36686 | 2023-05-29 04:21:07 | 307 | 185 | 2023-05-29 05:06:07 | 114.048676 | 22.566605 | 2700.0 | 542 |
| 307421 | 36805 | 2023-05-29 03:15:54 | 324 | 168 | 2023-05-29 04:14:40 | 114.065552 | 22.551100 | 3526.0 | 543 |
| 337431 | 36805 | 2023-05-29 04:23:40 | 325 | 132 | 2023-05-29 05:13:33 | 114.066521 | 22.519133 | 2993.0 | 544 |
545 rows × 9 columns
[14]:
move
[14]:
| id | SLONCOL | SLATCOL | stime | slon | slat | etime | elon | elat | ELONCOL | ELATCOL | duration | moveid | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 22396 | 253 | 326 | 2023-05-29 00:00:29 | 113.996719 | 22.693333 | 2023-05-29 06:10:09 | 114.005547 | 22.655800 | 262.0 | 284.0 | 22180.0 | 0 |
| 23320 | 22396 | 262 | 284 | 2023-05-29 07:56:32 | 114.005547 | 22.655800 | 2023-05-29 12:51:23 | 113.798630 | 22.786167 | 50.0 | 429.0 | 17691.0 | 1 |
| 51327 | 22396 | 50 | 429 | 2023-05-29 16:44:57 | 113.798630 | 22.786167 | 2023-05-29 23:59:55 | 114.025253 | 22.654900 | 283.0 | 283.0 | 26098.0 | 2 |
| 54670 | 22413 | 145 | 431 | 2023-05-29 00:00:09 | 113.891403 | 22.787300 | 2023-05-29 00:00:09 | 113.891403 | 22.787300 | 145.0 | 431.0 | 0.0 | 3 |
| 54670 | 22413 | 145 | 431 | 2023-05-29 01:22:41 | 113.891403 | 22.787300 | 2023-05-29 01:25:13 | 113.891701 | 22.787399 | 145.0 | 431.0 | 152.0 | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 154762 | 36686 | 307 | 185 | 2023-05-29 03:51:07 | 114.048721 | 22.566692 | 2023-05-29 04:21:07 | 114.048676 | 22.566605 | 307.0 | 185.0 | 1800.0 | 720 |
| 154924 | 36686 | 307 | 185 | 2023-05-29 05:06:07 | 114.048676 | 22.566605 | 2023-05-29 23:53:46 | 114.124580 | 22.571978 | 384.0 | 191.0 | 67659.0 | 721 |
| 135725 | 36805 | 328 | 147 | 2023-05-29 00:00:03 | 114.070030 | 22.531967 | 2023-05-29 03:15:54 | 114.065552 | 22.551100 | 324.0 | 168.0 | 11751.0 | 722 |
| 307421 | 36805 | 324 | 168 | 2023-05-29 04:14:40 | 114.065552 | 22.551100 | 2023-05-29 04:23:40 | 114.066521 | 22.519133 | 325.0 | 132.0 | 540.0 | 723 |
| 337431 | 36805 | 325 | 132 | 2023-05-29 05:13:33 | 114.066521 | 22.519133 | 2023-05-29 23:53:51 | 114.120354 | 22.544300 | 380.0 | 160.0 | 67218.0 | 724 |
725 rows × 13 columns
根据停靠点和行程信息,您可以对轨迹数据进行切片,以提取停靠点和行程期间的轨迹点。由于您之前已执行冗余消除,因此停靠点期间的冗余轨迹点已被移除。因此,与行程期间的轨迹数据相比,停靠点期间的轨迹数据将具有明显更少的数据点。
轨迹切片
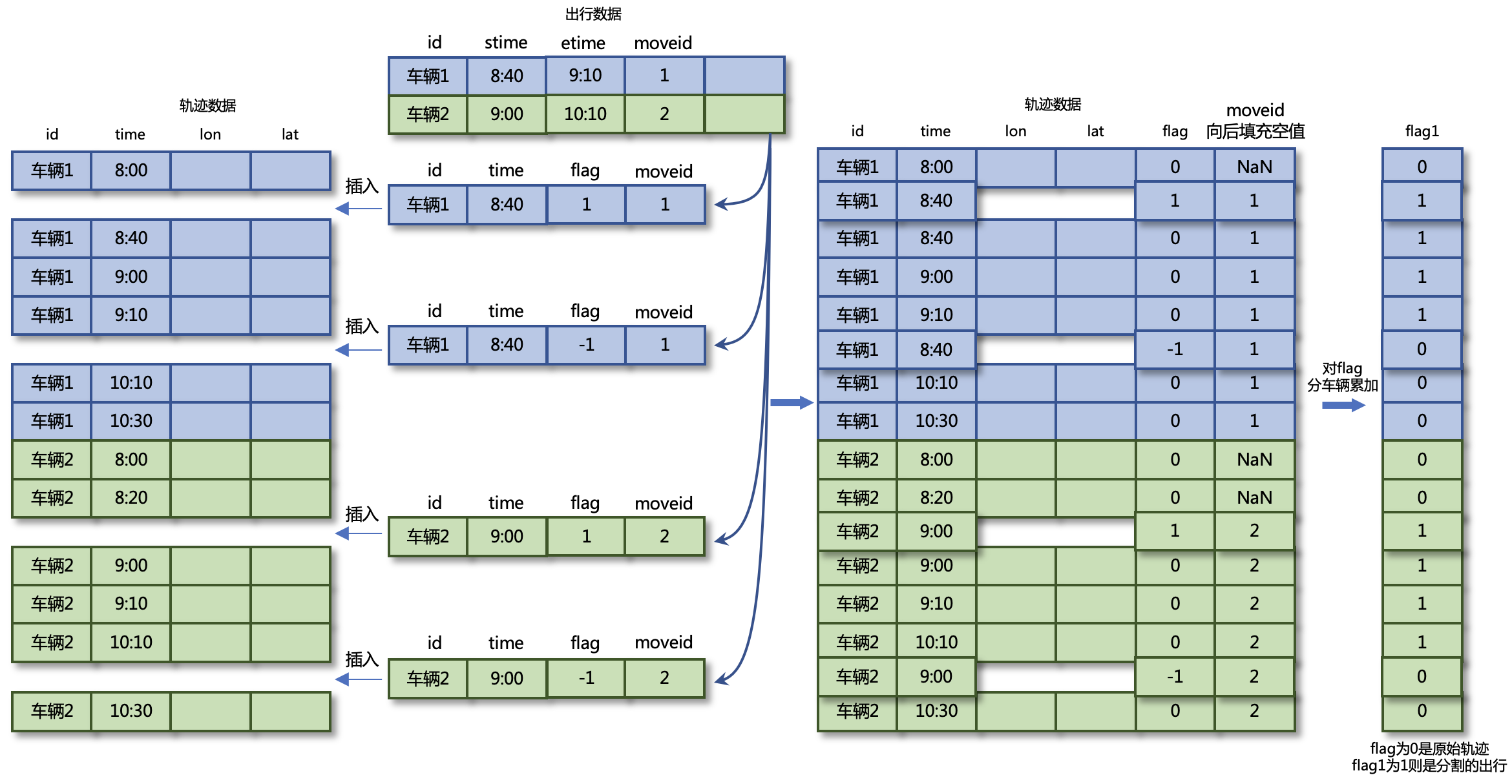
通过上述代码,已成功从数据中提取停车和旅行信息。但是,在获取的行程信息中,仅包含每次行程起点和终点的时间、纬度、经度信息,而不包含行程轨迹信息。为了进一步分析车辆的行驶轨迹,需要从每次行程的时间段中提取轨迹数据,即根据行驶信息对轨迹数据集进行切片。在先前计算的旅行信息中,每个旅行记录都有一个旅行 ID、开始时间和结束时间列。轨迹切片的结果是提取行程中的轨迹点,并为每个轨迹点分配一个行程 ID 标签。
下图说明了轨迹切片的概念。将为轨迹数据创建一个标志列,以标记每行是否在所需的切片时间段内。然后,将行程数据中的每个行程记录分解为开始时间记录(标志标签为 1)和结束时间记录(标志标签为 -1),并插入到轨迹数据中。接下来,对标志列进行分组并按车辆求和,以获得标志 1 列。在结果中,flag1 列值为 1(行程)和标志列值为 0(非临时插入的数据)的行是所需的轨迹数据。
可以使用“tbd.traj_slice”执行轨迹数据切片的代码,代码示例如下:
[18]:
# Extract trajectory points during parking
stay_points = tbd.traj_slice(data, stay, traj_col=['id', 'time'], slice_col=[
'id', 'stime', 'etime', 'stayid'])
stay_points
[18]:
| id | time | lon | lat | OpenStatus | speed | stayid | |
|---|---|---|---|---|---|---|---|
| 23320 | 22396 | 2023-05-29 06:10:09 | 114.005547 | 22.655800 | 0.0 | 1.0 | 0.0 |
| 23321 | 22396 | 2023-05-29 06:20:42 | 114.005547 | 22.655800 | 0.0 | 0.0 | 0.0 |
| 23322 | 22396 | 2023-05-29 06:25:09 | 114.005417 | 22.655767 | 0.0 | 0.0 | 0.0 |
| 23323 | 22396 | 2023-05-29 06:25:17 | 114.005417 | 22.655767 | 0.0 | 0.0 | 0.0 |
| 23324 | 22396 | 2023-05-29 06:30:09 | 114.005402 | 22.655767 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 307425 | 36805 | 2023-05-29 04:14:40 | 114.066452 | 22.550966 | 0.0 | 9.0 | 543.0 |
| 337431 | 36805 | 2023-05-29 04:23:40 | 114.066521 | 22.519133 | 0.0 | 20.0 | 544.0 |
| 337432 | 36805 | 2023-05-29 04:23:55 | 114.066521 | 22.519133 | 0.0 | 0.0 | 544.0 |
| 337433 | 36805 | 2023-05-29 05:13:27 | 114.066521 | 22.519133 | 1.0 | 0.0 | 544.0 |
| 337434 | 36805 | 2023-05-29 05:13:33 | 114.067230 | 22.519751 | 1.0 | 3.0 | 544.0 |
8428 rows × 7 columns
[19]:
# Extract trajectory points during travel
move_points = tbd.traj_slice(data, move, traj_col=['id', 'time'], slice_col=[
'id', 'stime', 'etime', 'moveid'])
move_points
[19]:
| id | time | lon | lat | OpenStatus | speed | moveid | |
|---|---|---|---|---|---|---|---|
| 0 | 22396 | 2023-05-29 00:00:29 | 113.996719 | 22.693333 | 1.0 | 20.0 | 0.0 |
| 27 | 22396 | 2023-05-29 00:01:01 | 113.995514 | 22.695032 | 1.0 | 34.0 | 0.0 |
| 28 | 22396 | 2023-05-29 00:01:09 | 113.995430 | 22.695766 | 1.0 | 41.0 | 0.0 |
| 29 | 22396 | 2023-05-29 00:01:41 | 113.995369 | 22.696484 | 1.0 | 0.0 | 0.0 |
| 30 | 22396 | 2023-05-29 00:02:21 | 113.995430 | 22.696650 | 1.0 | 17.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 132774 | 36805 | 2023-05-29 23:53:03 | 114.120354 | 22.544333 | 1.0 | 3.0 | 724.0 |
| 132775 | 36805 | 2023-05-29 23:53:09 | 114.120354 | 22.544300 | 1.0 | 2.0 | 724.0 |
| 132776 | 36805 | 2023-05-29 23:53:15 | 114.120354 | 22.544300 | 1.0 | 1.0 | 724.0 |
| 132777 | 36805 | 2023-05-29 23:53:21 | 114.120354 | 22.544300 | 1.0 | 0.0 | 724.0 |
| 132778 | 36805 | 2023-05-29 23:53:51 | 114.120354 | 22.544300 | 0.0 | 0.0 | 724.0 |
397892 rows × 7 columns
轨迹增密化和稀疏化
为了便于后续任务,例如将轨迹数据中的行驶路径与道路网络相匹配,我们在行驶过程中对轨迹点进行致密化或稀疏化。在此阶段,我们将 ID 列指定为行程 ID (moveid) 列,这意味着在对轨迹点执行致密化或稀疏化操作时,我们分别考虑每个行程。此操作的代码如下:
[59]:
# Trajectory densification
move_points_densified = tbd.traj_densify(
move_points, col=['moveid', 'time', 'lon', 'lat'], timegap=15)
move_points_densified
[59]:
| id | time | lon | lat | OpenStatus | speed | moveid | |
|---|---|---|---|---|---|---|---|
| 0 | 22396.0 | 2023-05-29 00:00:29 | 113.996719 | 22.693333 | 1.0 | 20.0 | 0.0 |
| 2 | NaN | 2023-05-29 00:00:30 | 113.996681 | 22.693386 | NaN | NaN | 0.0 |
| 3 | NaN | 2023-05-29 00:00:45 | 113.996116 | 22.694183 | NaN | NaN | 0.0 |
| 4 | NaN | 2023-05-29 00:01:00 | 113.995552 | 22.694979 | NaN | NaN | 0.0 |
| 1 | 22396.0 | 2023-05-29 00:01:01 | 113.995514 | 22.695032 | 1.0 | 34.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 397889 | 36805.0 | 2023-05-29 23:53:15 | 114.120354 | 22.544300 | 1.0 | 1.0 | 724.0 |
| 397890 | 36805.0 | 2023-05-29 23:53:21 | 114.120354 | 22.544300 | 1.0 | 0.0 | 724.0 |
| 4175974 | NaN | 2023-05-29 23:53:30 | 114.120354 | 22.544300 | NaN | NaN | 724.0 |
| 4175975 | NaN | 2023-05-29 23:53:45 | 114.120354 | 22.544300 | NaN | NaN | 724.0 |
| 397891 | 36805.0 | 2023-05-29 23:53:51 | 114.120354 | 22.544300 | 0.0 | 0.0 | 724.0 |
1211070 rows × 7 columns
[60]:
# Trajectory sparsification
move_points_sparsified = tbd.traj_sparsify(
move_points, col=['moveid', 'time', 'lon', 'lat'], timegap=120)
move_points_sparsified
[60]:
| id | time | lon | lat | OpenStatus | speed | moveid | |
|---|---|---|---|---|---|---|---|
| 0 | 22396 | 2023-05-29 00:00:29 | 113.996719 | 22.693333 | 1.0 | 20.0 | 0.0 |
| 4 | 22396 | 2023-05-29 00:02:21 | 113.995430 | 22.696650 | 1.0 | 17.0 | 0.0 |
| 7 | 22396 | 2023-05-29 00:04:21 | 113.992348 | 22.696733 | 0.0 | 36.0 | 0.0 |
| 10 | 22396 | 2023-05-29 00:06:21 | 113.986366 | 22.691000 | 0.0 | 48.0 | 0.0 |
| 12 | 22396 | 2023-05-29 00:08:21 | 113.989586 | 22.681749 | 0.0 | 43.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 397822 | 36805 | 2023-05-29 23:45:27 | 114.091217 | 22.540768 | 0.0 | 11.0 | 724.0 |
| 397835 | 36805 | 2023-05-29 23:47:21 | 114.093002 | 22.543383 | 1.0 | 0.0 | 724.0 |
| 397855 | 36805 | 2023-05-29 23:49:21 | 114.105850 | 22.545250 | 1.0 | 58.0 | 724.0 |
| 397875 | 36805 | 2023-05-29 23:51:21 | 114.119514 | 22.547033 | 1.0 | 24.0 | 724.0 |
| 397890 | 36805 | 2023-05-29 23:53:21 | 114.120354 | 22.544300 | 1.0 | 0.0 | 724.0 |
90172 rows × 7 columns
[ ]:
# define a function to plot the trajectory
def plot_traj(traj):
import folium
# 1. Create a map with the center at the average coordinates of the trajectory
m = folium.Map(location=[traj['lat'].mean(), traj['lon'].mean()], # Map center
zoom_start=14, # Map zoom level
tiles='cartodbpositron') # Map style
# 2. Add the trajectory
folium.PolyLine(
traj[['lat', 'lon']].values.tolist(), # Trajectory coordinates
color='red', # Trajectory color
weight=2.5, # Trajectory width
opacity=1).add_to(m) # Trajectory opacity, add to the map after creating the trajectory
# 3. Add trajectory points
for i in range(len(traj)):
folium.CircleMarker(
location=[traj['lat'].iloc[i], traj['lon'].iloc[i]], # Trajectory point coordinates
radius=3, # Trajectory point radius
color='red', # Trajectory point color
).add_to(m) # Fill opacity, add to the map after creating the trajectory point
# 4. Add start and end markers
folium.Marker([traj['lat'].iloc[0], traj['lon'].iloc[0]], # Start point coordinates
popup='Start', # Start marker label
icon=folium.Icon(color='green')).add_to(m) # Start marker color
folium.Marker([traj['lat'].iloc[-1], traj['lon'].iloc[-1]],
popup='End',
icon=folium.Icon(color='red')).add_to(m)
# 5. Display the map, directly in Jupyter Notebook
return m
[65]:
moveid = 51
# Original trajectory
traj = move_points[move_points['moveid']==moveid]
plot_traj(traj)
[65]:
[66]:
# Densified trajectory
traj = move_points_densified[move_points_densified['moveid']==moveid]
plot_traj(traj)
[66]:
[67]:
# Sparsified trajectory
traj = move_points_sparsified[move_points_sparsified['moveid']==moveid]
plot_traj(traj)
[67]:
轨迹平滑
在处理车辆轨迹数据时,轨迹点表示对车辆实际“状态”的“观察”。由于误差,观察到的数据可能与车辆的实际状态有所不同。
如何更准确地估计车辆的实际状态?考虑上一节中提到的检测轨迹漂移的方法,该方法涉及将轨迹点的位置与先前轨迹点的位置进行比较,以检查显着和不合理的跳跃。这种方法基本上基于根据车辆先前的轨迹预测车辆未来可能的位置。如果下一个记录的轨迹点明显偏离预期位置,则可以确定轨迹异常。
这种方法与卡尔曼滤波的概念有相似之处。卡尔曼滤波是一种线性二次估计算法,用于线性动态系统中的状态估计。它将先前的状态估计(即当前轨迹点的预测位置)与当前观测数据(当前轨迹点的记录位置)相结合,以获得当前状态的最优估计。
卡尔曼滤波的实现涉及使用先前的最佳结果预测当前值,然后使用观测值校正当前值以获得最佳结果。这种方法有效地减少了噪声的影响,可以更准确地估计车辆的实际状态。
[84]:
move_id =51
traj = move_points[move_points['moveid'] == move_id].copy()
traj_smoothed = tbd.traj_smooth(traj,col = ['id','time','lon', 'lat'],proj=False,process_noise_std = 0.01, measurement_noise_std = 1)
[85]:
# plot the trajectory
import folium
m = folium.Map(location=[traj['lat'].mean(), traj['lon'].mean()],
zoom_start=14,
tiles='cartodbpositron')
# original trajectory
folium.PolyLine(
traj[['lat', 'lon']].values.tolist(),
color='red',
weight=2.5,
opacity=1).add_to(m)
# smoothed trajectory
folium.PolyLine(
traj_smoothed[['lat', 'lon']].values.tolist(),
color='blue',
weight=2.5,
opacity=1).add_to(m)
m
[85]:
卡尔曼滤波器的目标是通过估计系统状态来优化观测值,同时考虑观测噪声和系统动力学的不确定性。它通过减少噪声影响和最小化小范围内的波动,在平滑轨迹数据方面具有优势。然而,卡尔曼滤波器不能完全消除所有噪声或处理轨迹漂移。
卡尔曼滤波器适用于轨迹数据中噪声相对稳定的情况,这意味着噪声方差保持不变。它在平滑由轨迹数据中的测量误差引起的小规模波动方面特别有效。
然而,当轨迹中出现显著漂移时,卡尔曼滤波器的有效性是有限的。漂移点被视为观测值,对状态估计有重大影响,卡尔曼滤波器无法直接处理。
此外,卡尔曼滤波需要指定过程误差和观测误差的协方差矩阵,这些参数设置会影响平滑效果。不正确的协方差矩阵设置可能会导致平滑轨迹数据出现显著偏差,尤其是在处理可能偏离道路网络的轨迹数据时。
在处理轨迹数据时,常见的方法是先去除漂移,然后进行平滑,最后进行路网匹配。这种方法背后的基本原理如下:
漂移消除步骤消除了数据中的明显漂移点,这些漂移点是大噪声分量。漂移点的存在会严重干扰后续处理步骤。去除或校正漂移点可确保后续处理的准确性和可靠性。
去除漂移后,轨迹数据可能仍包含一些噪声和波动。为了减少这些噪声和波动的影响,可以应用平滑来进一步处理轨迹数据,使其更平滑、更连续,并保持轨迹的整体趋势。
最后,平滑后的轨迹更稳定,更适合路网匹配。它减少了噪声和波动引起的误差,从而提高了路网匹配的准确性和可靠性。