轨迹处理
|
删除轨迹数据中的漂移。 |
|
删除与前后数据信息相同的数据,以减少数据量。 |
|
根据切片数据对轨迹数据进行切片。 |
|
使用卡尔曼滤波器的平滑轨迹。 |
|
按顺序分割轨迹,返回每段的起点和终点信息。 |
|
轨迹致密化,保证每个时间间隔秒都有一个轨迹点 |
|
轨迹稀疏化。 |
|
输入轨迹数据和栅格化参数,识别停留和移动 |
|
输入轨迹,生成GeoDataFrame |
|
最近地图匹配:查找道路网络上每个轨迹点的最近点。 |
|
计算轨迹长度。 |
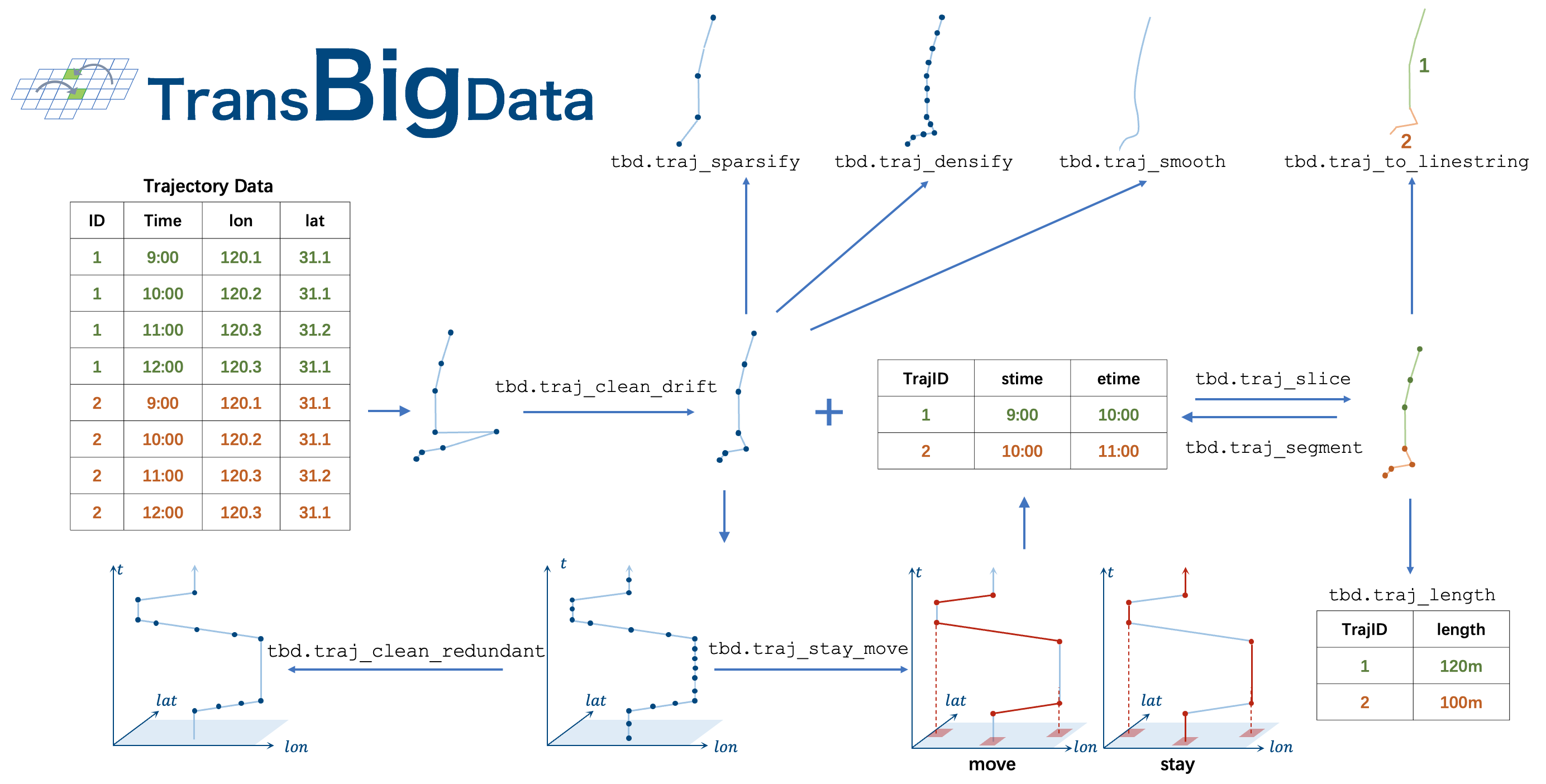
- transbigdata.traj_clean_drift(data, col=['VehicleNum', 'Time', 'Lng', 'Lat'], method='twoside', speedlimit=80, dislimit=1000, anglelimit=30)
删除轨迹数据中的漂移。漂移定义为速度大于速度限制或当前点与下一个点之间的距离大于距离限制或当前点与前一点和下一个点之间的角度小于角度限制的数据。限速默认为80km/h,距离限制默认为1000m。清理漂移数据的方法分为两种方法:“单侧”和“双侧”。“单面”法是考虑当前点和下一个点的速度,“双边”法是考虑当前点、前一点和下一个点的速度。
- 参数:
data (DataFrame) – 数据
col (List) – 列名,顺序为[‘VehicleNum’, ‘Time’, ‘Lng’, ‘Lat’]
method (string) – 清洗漂移数据的方法,包括‘oneside’和‘twoside’
speedlimit (number) – 限速
dislimit (number) – 距离限制
anglelimit (number) – 角度限制
- 返回:
data1 – 清理后的数据
- 返回类型:
DataFrame
- transbigdata.traj_clean_redundant(data, col=['VehicleNum', 'Time', 'Lng', 'Lat'])
删除与前后数据信息相同的数据,以减少数据量。例如,如果一个人的几个连续数据具有相同的信息,除了时间,则只能保留第一个和最后两个数据
- 参数:
data (DataFrame) – 数据
col (List) – 列名称,按 [‘车辆 ID, 时间’] 的顺序排列。它会按时间排序,然后确定时间以外的其他列的信息
- 返回:
data1 – 清理后的数据
- 返回类型:
DataFrame
- transbigdata.traj_slice(traj_data, slice_data, traj_col=['vid', 'time'], slice_col=['vid', 'stime', 'etime', 'tripid'])
根据切片数据对轨迹数据进行切片。该方法根据指定的时间段(slice_data)从一组给定的轨迹数据(traj_data)中提取数据。
- 参数:
traj_data (DataFrame) – 轨迹数据,包含每辆车的轨迹
slice_data (DataFrame) – 切片数据,包含每个切片的开始时间、结束时间和车辆ID
traj_col (List) – 轨迹数据的列名,顺序为[VehicleNum,Time]
slice_col (List) – 切片数据的列名,按 [VehicleNum_slice、Stime、Etime、SliceId] 的顺序排列
- 返回:
data_sliced – 切片轨迹数据
- 返回类型:
DataFrame
示例
>>> tbd.traj_slice(GPSData, move, traj_col=['vid', 'time'], slice_col = ['vid','stime','etime','tripid'])
- transbigdata.traj_smooth(data, col=['id', 'time', 'lon', 'lat'], proj=False, process_noise_std=0.5, measurement_noise_std=1)
使用卡尔曼滤波器的平滑轨迹。
- 参数:
data (DataFrame) – 轨迹数据
col (list) – 轨迹数据的列名
proj (bool) – 是否进行等距投影
process_noise_std (float) – 过程噪声的标准偏差
measurement_noise_std (float) – 测量噪声的标准偏差
- 返回:
data – 平滑轨迹数据
- 返回类型:
DataFrame
- transbigdata.traj_segment(data, groupby_col=['id', 'moveid'], retain_col=['time', 'lon', 'lat'])
按顺序分割轨迹,返回每段的起点和终点信息。该功能可以分割GPS轨迹数据,计算每个线段的起点和终点信息,并将结果存储在DataFrame对象中。此函数的输入包括一个 pandas 数据帧对象,其中包含 GPS 轨迹数据、用于分组的字段名称和要保留的字段名称。输出是一个 pandas DataFrame 对象,其中包含每个线段的开始和结束信息,其中每行表示一个轨迹段。
- 参数:
data (DataFrame) – 轨迹数据需要预先排序。
groupby_col (List) – 指定要用于分段的分组依据字段的字符串列表。
retain_col (List) – 指定要保留的字段的字符串列表。
- 返回:
data – 包含每个线段的开始和结束信息,其中每行表示一个轨迹段。
- 返回类型:
DataFrame
- transbigdata.traj_densify(data, col=['Vehicleid', 'Time', 'Lng', 'Lat'], timegap=15)
轨迹致密化,保证每个时间间隔秒都有一个轨迹点
- 参数:
data (DataFrame) – 数据
col (List) – 列名,顺序为[Vehicleid, Time, lng, lat]
timegap (number) – 采样间隔(秒)
- 返回:
data1 – 处理后的数据
- 返回类型:
DataFrame
- transbigdata.traj_sparsify(data, col=['Vehicleid', 'Time', 'Lng', 'Lat'], timegap=15, method='subsample')
轨迹稀疏。当轨迹数据的采样频率过高时,数据量太大,这对于一些需要较少数据频率的研究进行分析是不方便的。此功能可以扩展采样间隔并减少数据量。
- 参数:
data (DataFrame) – 数据
col (List) – 列名,顺序为[Vehicleid, Time, lng, lat]
timegap (number) – 轨迹点之间的时间间隔
method (str) – ‘插值’或’子样本’
- 返回:
data1 – 稀疏轨迹数据
- 返回类型:
DataFrame
- transbigdata.traj_stay_move(data, params, col=['ID', 'dataTime', 'longitude', 'latitude'], activitytime=1800)
输入轨迹数据和栅格化参数,识别停留和移动
- 参数:
data (DataFrame) – 轨迹数据
params (List) – 栅格化参数
col (List) – 列名,顺序为[‘ID’,’dataTime’,’longitude’,’latitude’]
activitytime (Number) – 多少时间算活动
- 返回:
stay (DataFrame) – 停留信息
move (DataFrame) – 移动信息
- transbigdata.traj_to_linestring(traj_points, col=['Lng', 'Lat', 'ID'], timecol=None)
输入轨迹,生成GeoDataFrame
- 参数:
traj_points (DataFrame) – 轨迹数据
col (List) – 列名,顺序为[lng,lat,trajectoryid]
timecol (str(Optional)) – 可选,时间列的列名。如果给定,可以将返回的带有[经度,纬度,高度,时间]的geojson放入开普勒中以可视化轨迹
- 返回:
traj – 生成的轨迹
- 返回类型:
GeoDataFrame
- transbigdata.traj_mapmatch(traj, G, col=['lon', 'lat'])
最近地图匹配:查找道路网络上每个轨迹点的最近点。在进行最近邻匹配时,我们需要找到路网中每个轨迹点最近的路段,并将轨迹点与该路段进行匹配。在实践中,我们可以先提取路段的节点形成一组点(即从几何列中的每个 LineString 中提取每个坐标点),然后计算轨迹点与这组点之间的最近距离,最后将轨迹点与最近距离节点所在的路段匹配。这个过程有效地将点与线的匹配问题转化为点与点的匹配问题。
- 参数:
traj (DataFrame) – 待匹配的轨迹点数据集。
G (networkx multidigraph) – 用于匹配的路网,由osmnx创建。
col (list) – 轨迹点数据集中经度和纬度列的名称。
- 返回:
traj_matched – 匹配后的轨迹点数据集。
- 返回类型:
DataFrame
- transbigdata.traj_length(move_points, col=['lon', 'lat', 'moveid'], method='Haversine')
计算轨迹长度。输入轨迹点数据并计算每个轨迹的长度(以米为单位)。
- 参数:
move_points (DataFrame) – 轨迹点数据,包括轨迹ID、经度、纬度等。通过轨迹 id 区分不同的轨迹,轨迹点按时间顺序排列。
col (list) – Column names of the trajectory point data, in the order of [longitude, latitude, trajectory id]
method (str) – 计算轨迹长度的方法,可选“Haversine”或“Project”,默认为“Haversine”,使用球面三角公式计算距离,“Project”将数据转换为投影坐标系以计算平面距离。
- 返回:
move_trajs – 轨迹长度数据,包括轨迹 id 和轨迹长度两列,单位为米。
- 返回类型:
DataFrame