数据可视化
|
输入是数据点,此函数将聚合然后可视化 |
|
输入的是轨迹数据和列名。 |
|
输入是OD数据和列。 |
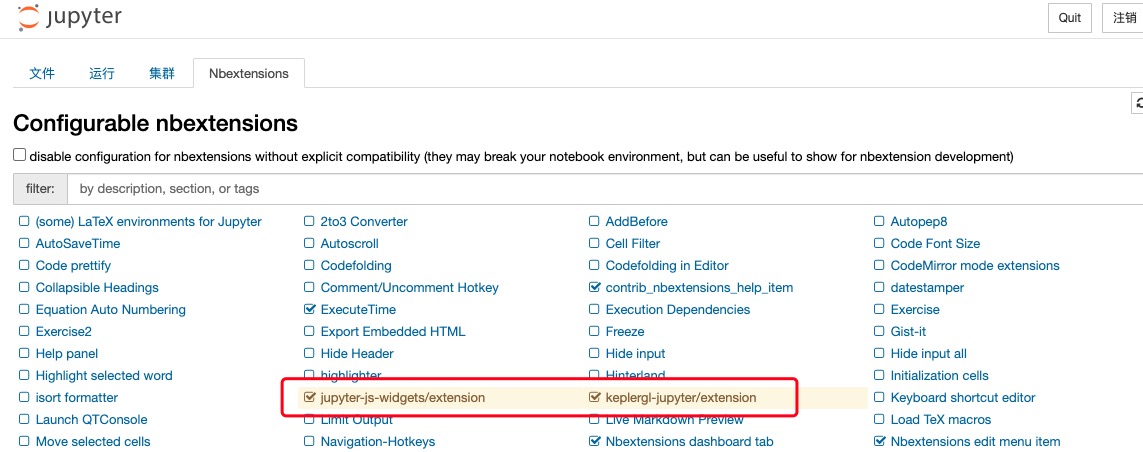
在jupyter中显示可视化的设置
pip install keplergl
如果要在jupyter notebook中显示可视化,则需要勾选jupyter-js-widgets(可能需要另外安装)和keplergl-jupyter两个插件
数据点分布可视化
- transbigdata.visualization_data(data, col=['lon', 'lat'], accuracy=500, height=500, maptype='point', zoom='auto')
输入是数据点,此函数将聚合然后可视化
- 参数:
data (DataFrame) – 数据点
col (List) – 列名。用户可以按[经度,纬度]的顺序选择非权重的起点-目的地(OD)数据。为此,聚合是自动的。或者,用户也可以输入加权OD数据,按[经度、纬度、计数]的顺序排列。
zoom (number) – 地图缩放级别(可选)。
height (number) – 地图框的高度
accuracy (number) – 栅格大小
maptype (str) – 地图类型,‘点’或‘热图’
- 返回:
vmap – keplergl 提供的可视化
- 返回类型:
keplergl.keplergl.KeplerGl
轨道可视化
- transbigdata.visualization_trip(trajdata, col=['Lng', 'Lat', 'ID', 'Time'], zoom='auto', height=500)
输入是轨迹数据和列名称。输出是基于开普勒的可视化结果
- 参数:
trajdata (DataFrame) – 轨迹点数据
col (List) – 列名称,按 [经度、纬度、车辆 ID、时间] 的顺序排列
zoom (number) – 地图缩放级别
height (number) – 地图框的高度
- 返回:
vmap – keplergl 提供的可视化
- 返回类型:
keplergl.keplergl.KeplerGl
OD可视化
- transbigdata.visualization_od(oddata, col=['slon', 'slat', 'elon', 'elat'], zoom='auto', height=500, accuracy=500, mincount=0)
输入是 OD 数据和列。输出是基于开普勒的可视化结果
- 参数:
oddata (DataFrame) – 外径数据
col (List) – 列名。用户可以按[原点经度、原点纬度、目的地经度、目的地纬度]的顺序选择非权重的起点-目的地(OD)数据。为此,聚合是自动的。或者,用户也可以输入加权OD数据,按[原点经度、原点纬度、目的地经度、目的地纬度、计数]的顺序排列。
zoom (number) – 地图缩放级别(可选)。
height (number) – 地图框的高度
accuracy (number) – 栅格大小
mincount (number) – 最小OD数,OD数少的不显示
- 返回:
vmap – keplergl 提供的可视化
- 返回类型:
keplergl.keplergl.KeplerGl